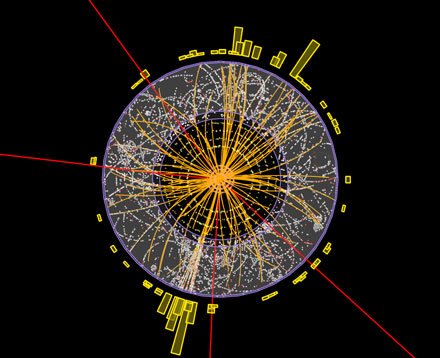
First of all: what does statistics have to do with the Higgs boson findings? It seems that there would be no need for it - either you've seen the God particle, or you haven't seen the Goddamn particle. But since the Higgs boson is so minuscule, it can't be observed directly. The only chance of detecting it is to look for anomalies in the data from the Large Hadron Collider. There will always be some fluctuations in the data, so you have to look for anomalies that (a) are large enough and (b) are consistent with the properties of the hypothesised Higgs particle.
What the two teams at CERN reported yesterday is that both teams have found largish anomalies in the same region, independently of each other. They quantify how large the anomalies are by describing them as, for instance, as being roughly "two sigma events". Events that have more sigmas, or standard deviations, associated with them are less likely to happen if there is no Higgs boson. Two sigma events are fairly rare: if there is no Higgs boson then anomalies at least as large as these would only appear in one experiment out of 20. This probability is known as the p-value of the results.
This is were the misinterpretation comes into play. Virtually every single news report on the Higgs findings seem to present a two sigma event as meaning that there is a 1/20 probability of the results being due to chance. Or in other words, that there is a 19/20 probability that the Higgs boson has been found.
In what I think is an excellent explanation of the difference, David Spiegelhalter attributed the misunderstanding to a missing comma:
The number of sigmas does not say 'how unlikely the result is due to chance': it measures 'how unlikely the result is, due to chance'.
The difference may seem subtle... but it's not. The number of sigmas, or the p-value, only tells you how often you would see this kind of results if there was no Higgs boson. That is not the same as the probability of there being such a particle - there either is or isn't a Higgs particle. Its existence is independent of the experiments and therefore the experiments don't tell us anything about the probability of the existence.
What we can say, then, is only that the teams at CERN have found anomalies that suspiciously large, but not so large that we feel that they can't be due simply to chance. Even if there was no Higgs boson, anomalies of this size would appear in roughly one experiment out of twenty, which means that they are slightly more common than getting five heads in a row when flipping a coin.
If you flip a coin five times and got only heads, you wouldn't say that since the p-value is 0.03, there is a 97 % chance that the coin only gives heads. The coin either is or isn't unbalanced. You can't make statements about the probability of it being unbalanced without having some prior information about how often coins are balanced and unbalanced.
The experiments at CERN are no different from coin flips, but there is no prior information about in how many universes the Higgs boson exists. That's why the scientists are reluctant to say that they've found it. That's why they need to make more measurement. That's why two teams are working independently from each other. That's why there isn't a 95 % chance that the Higgs boson has been found.
David Spiegelhalter tweeted about his Higgs post with the words "BBC wrong in describing evidence for the Higgs Boson, nerdy pedantic statistician claims". Is it pedantic to point out that people are fooling themselves?
I wholeheartedly recommend the Wikipedia list of seven common misunderstandings about the p-value.






{kind=link}